Projects

RSINet: Inpainting Remotely Sensed Images Using Triple GAN Framework
We tackle the problem of image inpainting in the remote sensing domain. We propose a novel inpainting method that individually focuses on each aspect of an image such as edges, colour and texture using a task specific GAN. Moreover, each individual GAN also incorporates the attention mechanism thatexplicitly extracts the spectral and spatial features. To ensure consistent gradient flow, the model uses residual learning paradigm, thus simultaneously working with high and low level features. We evaluate our model, along with previous state of the art models, on the two well known remote sensing datasets, Open Cities AI and Earth on Canvas, and achieve better performance. [Paper] [Code]
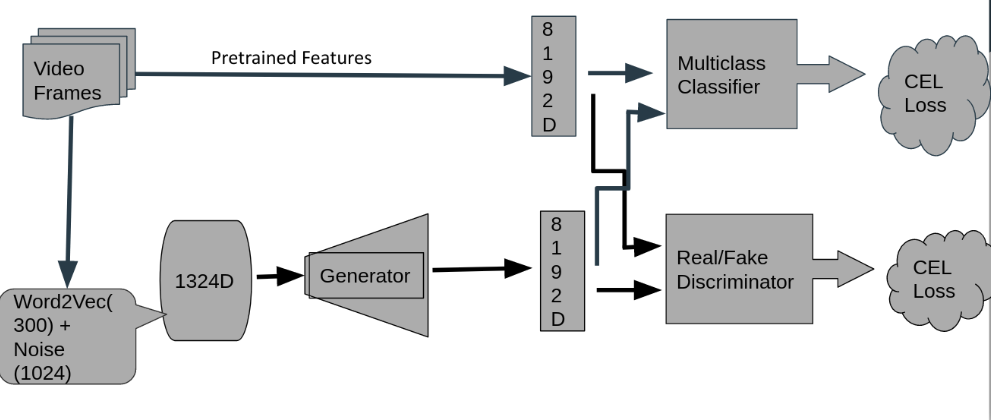
Video Action Recognition using Generalised Zero Shot Learning (B.Tech Project - Ongoing)
Generalised zero shot learning is a well studied problem wherein the model has to be trained in such a way that it is able to identify samples that come from completely unseen classes during deployment. We apply this method to video action recognition, namely, the UCF101 and the Large Human Motion Database(HMDB51) datasets. We propose a novel Generative Adversarial Network for this task which sets the benchmark for these datasets. Furthermore, we train the model incrementally, so as to gain better knowledge about the influence of training in different orders and perform various ablation studies. [Slides] [Code]

Improved Regularisation for Automatic Data Augmentation (Research Project - Ongoing)
Learning from visual observations is a challenging problem in Reinforcement Learning. Although CNNs have proven to be quite successful, the method still fails on Data efficiency and Generalization to new environments. The DrAC model proposes 2 regularisation terms for the policy and value functions over RAD which achieves state-of-the-art results on the Procgen benchmarks. We will be looking at setting up a baseline on Procgen benchmarks ourselves and extend it further by using different algorithms for selecting the appropriate augmentation, and also practically experiment and find out best regularization functions for policy and value functions to optimize performance. [Slides] [Report]
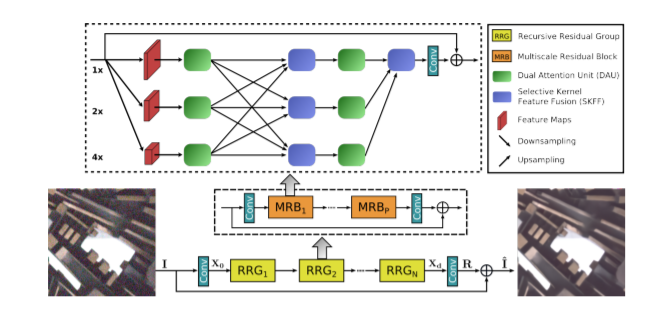
Low Light Noise Removal using CNN
With the aim of restoring high-quality image content from its degraded version, image restoration has numerous applications. Lately, convolutional neural networks (CNNs) have achieved dramatic improvements over conventional approaches for image restoration task. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. In this project, we study an architecture with the collective goals of maintaining spatially precise high-resolution representations through the entire network, and receiving strong contextual information from the low-resolution representations. We understand the functioning of the architecture and suggest modifications which can be done to further improve the performance depending on various use-cases. [Slides] [Report]
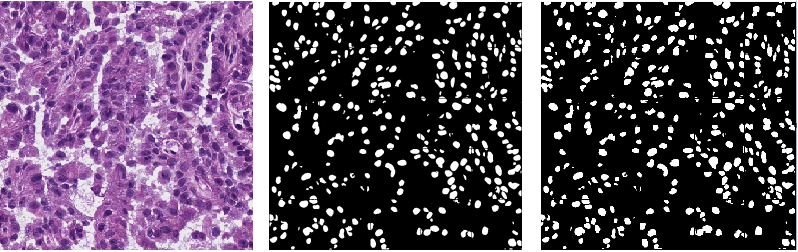
Multi-Organ Nuclei Segmentation (MoNuSeg)
Nuclear segmentation in digital microscopic tissue images could enable the extraction of high-quality features for nuclear morphometrics and other analysis in computational pathology. Techniques that accurately segment nuclei in diverse tissue images spanning a range of patients, organs, and disease states, can significantly contribute to the development of clinical and medical research software. As part of the MoNuSeg challenge (official satellite event of MICCAI 2018) I present my submission, which is a combination of the HRNet model with gated attention layers applied to it at relevant locations. It was able to achieve an Aggregated Jaccard Index (AJI) score of 0.6731 which was in the top 10 of the leaderboard. [Code] [Challenge]

Optical Character Reader
Developed an Optical Character Reader for detecting typed as well as handwritten text. This was presented in the tech expo 2019 held at IIT Bombay. [Code]
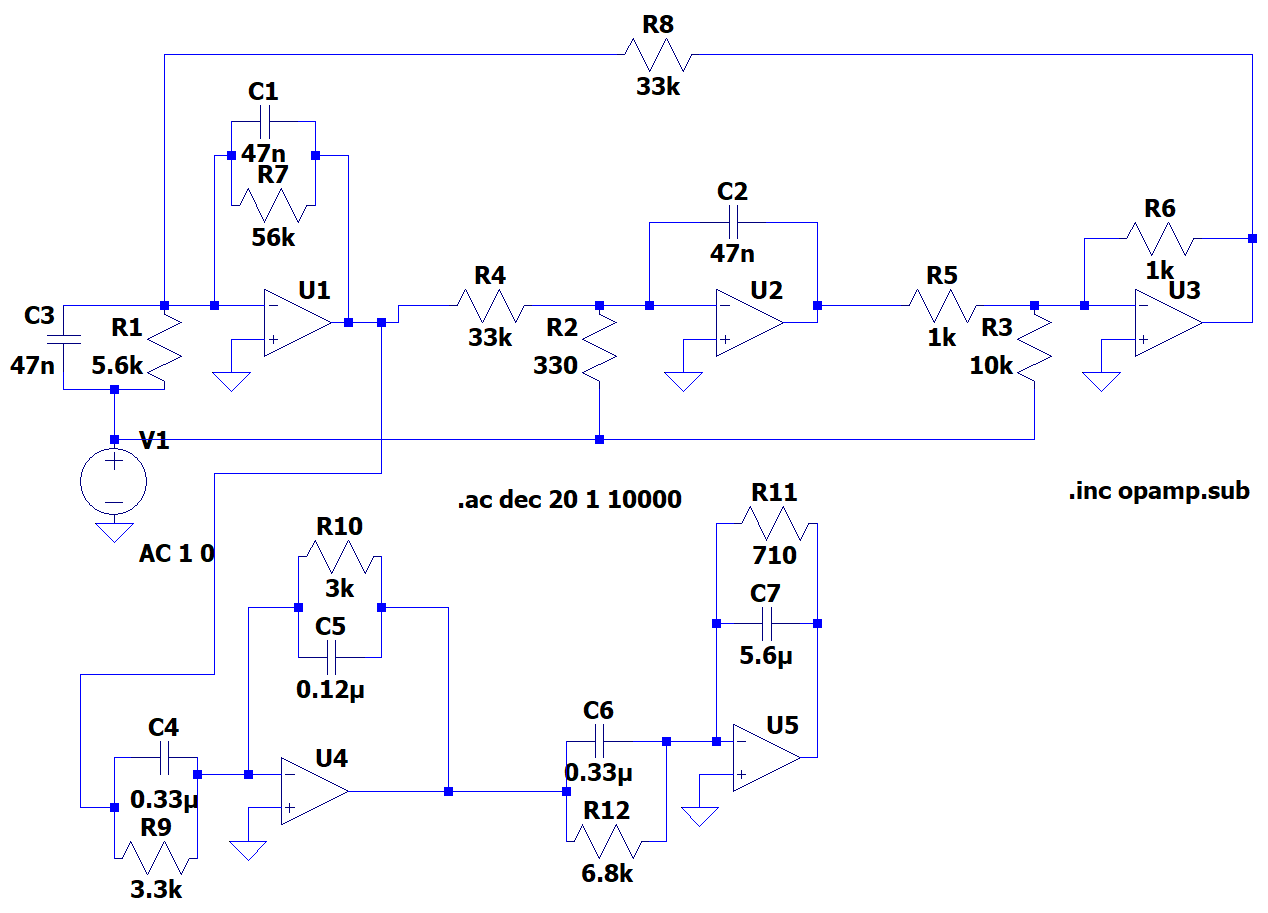
Compensator Design
Implemented a compensator ciruit based on the data given about the input and the output values of a black box structure. [Code] [Report]
Online Courses
- Natural Language Processing with Deep Learning (CS224n) : Completed the winter 2020 offering of the course by Stanford. Solutions to the assignments can be found here
- Convolutional Neural Networks for Visual Recognition (CS231n) : Completed the winter 2020 offering of the course by Stanford. Solutions to the assignments can be found here
- Machine Learning Specialization by Andrew Ng (Coursera) : Completed the online course on Machine Learning offered by Coursera. Solutions to the assignments can be found here
- Deep Reinforcement Learning by WildML.com : Completed the online course on deep reinforcement learning offered by wildml.com . Solutions to the various implementations can be found here